 GFS学习
GFS学习
# 分布式存储系统为什么很难
为了性能 -》需要分片
为了解决错误 -》需要容错
为了容错,需要复制 -》为了复制,需要解决一致性
为了一致性 -》 性能降低
因此分布式系统的构建,其中的难点就是一个死循环,而如何打破这种死循环,就需要平衡各方面的因素,以及设计更好的数据格式来处理相应的问题,比如用日志而非数据库存储状态提高效率,比如追求弱一致性而非强一致性
# GFS架构
# 适用场景:
发生故障是常态,系统能够自己从错误中快速恢复,避免错误。
系统存储了适当数量的大型文件,每个通常是100M或则更大。
系统主要面对2种读操作:
- 大型流式读
- 随机小型读
一次写入多次读取
系统必须保证多客户端对相同文件并发append的高效和原子性。
持久稳定的带宽
翻译原文:https://kb.cnblogs.com/page/174130/
# 架构图
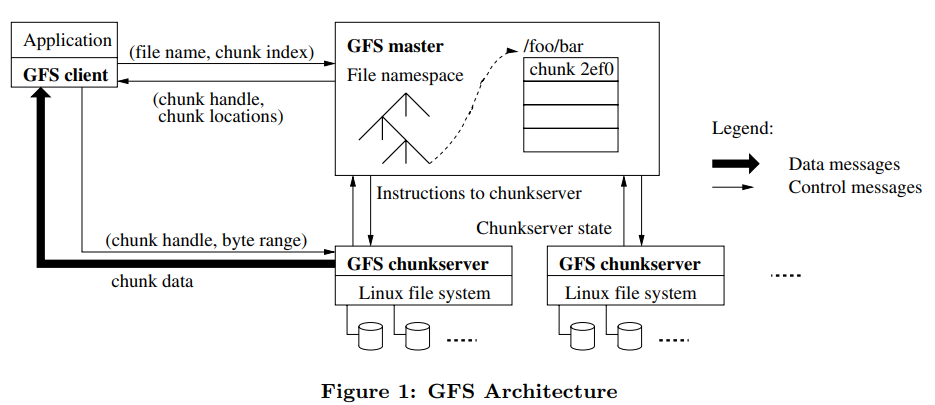
每一个GFS中的文件会被分成大小为64MB的块,这样的块被存储在不同的块服务器上
每一个块会有三个它自己的备份,备份被存储在其它的块服务器上
GFS系统中只有一个主机服务器,同时主机服务器的状态被备份在其它的服务器上
主机服务器主要处理文件的命名空间以及文件与块的映射,而其它块服务器用来发送数据给客户
# 主机状态及管理
所有状态数据都存放在主机服务器的内存中,包括:
- 文件名与它的每个文件块标识之间的映射,需要被持久化到主机服务器的硬盘上
文件块标识,包括:
块的版本号,需要被持久化到主机服务器的硬盘上
块和它的备份所在的块服务器的位置
块所在的块服务器是否是主要服务器
块的租用时间
需要持久化的状态数据会被写进日志,同时写入服务器硬盘的还有对主机状态的定期检查点
对于整个系统而言也会定时创建快照
# 文件读写
# 读文件
客户向主机服务器发送文件名和偏移量。
主机服务器根据文件名和偏移量查找对应的块
主机服务器并将含有最新版本号的块和它的备份的标识符和所在的块服务器地址返回给客户
客户将块标识符和块服务器位置缓存到本地
客户向离他最近的块服务器发送读请求
块服务器将数据返回给客户
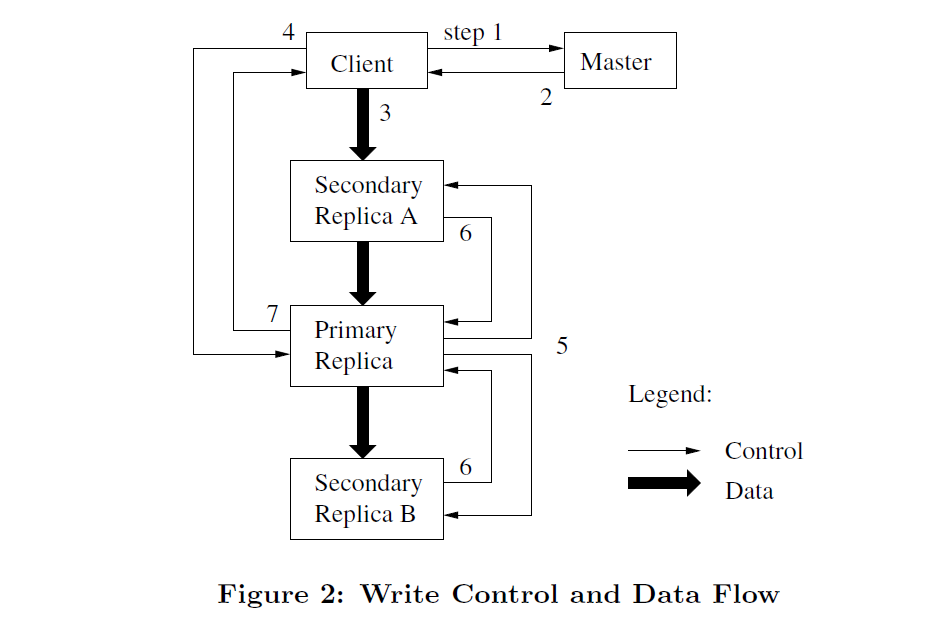
# 写文件
- 客户向主机服务器询问目标文件的尾部所在的块。
- 如果当前块没有对应的主块服务器:
- 如果没有任何块服务器含有该块的最新版本,返回错误给客户。
- 随机选取一个含有该块最新版本的块服务器作为主块服务器,其它含有最新版本的块服务器则称为从块服务器。
- 将块的版本号+1,并写入操作日志。
- 将新的版本号和各块服务器的职责发送给块服务器们。
- 块服务器们将新版本号写到本地本地硬盘中。
- 主机服务器将主块服务器和从块服务器返回给客户。
- 客户端将数据发送给所有对应的块服务器。
- 当所有对应的块服务器收到客户端发来的数据之后,客户端向主块服务器发送写请求。
- 主块服务器检查当前的块的租用时间是否到期,以及块的空间是否足够。
- 主块服务器挑选偏移量并将数据写入一个新的linux文件。
- 主块服务器通知其它从块服务器以相同顺序执行相同操作。
- 只有当所有从块服务器的写请求都返回成功,主块服务器才会返回成功给客户。
- 否则主块服务器会返回错误给客户。
- 当客户碰到错误时,他会重新发送同样请求给主服务器。
# 对GFS数据的一致性的各种影响因素:
- 考虑GFS会如何处理以下情型:
- 服务器宕机。
- 服务器宕机+重启。
- 服务器宕机+被替换。
- 请求或者响应消息丢失。
- 网络局部失败。
- 可能出现的具体问题:
- 当客户缓存了一个过期的主块服务器位置并发送写请求。
- 当客户缓存了一个过期的从块服务器位置并发送读请求。
- 当主机服务器宕机重启之后,它是否会遗忘上次处理的文件,或者遗忘哪些块服务器含有上次处理的文件对应的块?
- 当两个客户同时往同一个文件尾部写数据,它们新增的文件记录会互相覆盖吗?
- 假设有一个从块服务器一直没有收到主块服务器的写请求,而同时有个客户想要访问它上面的数据。
- 当主块服务器在发送写请求给其它从块服务器时宕机了,主机服务器会从从块服务器里面选择一个作为新的主块服务器么?
- 当一个从块服务器下线了,然后主块服务器和其它从块服务器运行一段时间后全部宕机,此时之前的从块服务器恢复上线了,主机服务器会选择它作为新的主块服务器么?
- 当某个从块服务器的写请求一直失败的时候,主块服务器要怎么做?
- 或者一直发送写请求给坏掉的块服务器?
- 或者将坏掉的块服务器从列表里面删除,然后返回成功给客户?
- 当主块服务器正常工作,但是因为网络原因主机服务器无法与它通信(,但是它可以跟主机服务器通信):
- 主机服务器会选择一个新的主块服务器么?
- 这就是split-brain的场景。
- 当一个正在执行分区写请求操作的主块服务器宕机了,然后主机服务器选择了一个新的主块服务器。新的主块服务器上的数据是最新的么?
- 如果当主机服务器彻底宕机了,它的替代品能获得之前的主机服务器的状态么?
- 如何确定主机服务器是否宕机?也许主机服务器的备份机可以ping当前的主机服务器,确认宕机之后尝试替代它?
- 当整个数据中心断电后又恢复了,所有的服务器重启。
- 当主机服务器因为某个块的备份太少想要创建一个新备份时,然后当前块是作为某个文件的最后一个块被写入。新的快备份如何确定它是否丢失之前块里的数据?
- 下列情型会让GFS彻底失去一致性的保证:
- 主机服务器和他的备份的状态全部丢失。
- 块服务器的硬盘数据丢失。
- CPU, 内存,网络或者硬盘返回不正确的值。(会导致checksum失效)
- 各个服务器的时间不一致。(会导致租赁机制失效)
- GFS允许一些应用程序可见的异常情况:
- 所有的客户会看见同样的数据么?
- 两个客户端看到不一样的数据。
- 一个客户端读取文件两遍看到不一样的数据。
- 所有客户端能看到相同顺序的写请求。
- 这些异常会对应用程序,比如map-reduce造成影响么?
- 所有的客户会看见同样的数据么?
- 为了获得强一致性要实现的机制:
- 主块服务器需要检测来自客户的重复的写请求,从而保证写的顺序一致。
- 所有的从块服务器需要完成每一个写请求,或者一个写请求都不完成。(可以用暂时的写请求直到真正需要写请求的时候)
- 当主块服务器宕机时,新选出的主块服务器需要通信其它的从块服务器以获取最近执行过的操作。
- 为了回避客户会从旧的从块服务器读取数据的问题,或者让所有客户都去主块服务器读取数据,或者从块服务器自己也需要有租赁机制。
# 实现原理
一个master 服务器用来管理 命名和追踪 chunk server中的chunk信息,每个chunk大小是64M,想读取数据时,就询问 master chunk在哪里
master 主要存储了两个table
- 一个是 filename -- chunk Id (或 chunk handle) 数组的映射 为了找到chunk
- 第二张表记录了 chunk -handle 到数据之间的映射,其中一项是chunk servers 列表,每个chunk 都有当前的版本号
所有的写操作,必须在chunk primary 上顺序化 ,master会记录哪个chunk server 是primary,并且只能在某个租约内担任primary,所以master 中有记录有过期时间,这些东西都存储在RAM 中,为了保证数据可靠,通常都会保存到硬盘上,且写入日志,通过建立chekpoint的方式,重启后会和其他chunk通信询问他们保存了哪些数据,重启后就不知道谁是primary 。
# 为什么使用日志 而不是数据库?
- 使用日志是因为追加日志非常高效,在一次磁盘旋转后,一次把他们写入磁盘上某个位置,这个位置包含了日志文件的结尾 end of the log 即 (EOF),如果使用b-tree 的话,需要去磁盘上寻找一个随机位置写入一点数据
# GFS的优缺点比较:
| 优点 | 缺点 |
|---|---|
| 将一个全局的文件系统集群作为基础设施 | 单主机服务器的处理性能存在瓶颈 |
| 将存储数据和命名映射的处理分离开来 | 对于小型文件来说块服务器性能不高 |
| 将大型文件分片从而方便并行处理 | 缺乏对主机服务器的自动恢复机制 |
| 将大型文件分片也降低了各个服务器的负担 | 数据一致性过于松散 |
| 采用主从方式顺序写文件 | |
| 采用租赁机制防止出现同时有两个主块服务器出现的情型 |
# 参考链接
- https://note.youdao.com/ynoteshare1/index.html?id=8d39d88b3ba7dd4f207fc5e184acde9a&type=note
- https://kb.cnblogs.com/page/174130/